热点文献带您关注AI与边缘计算——图书馆前沿文献专题推荐服务(37)
2021-04-08

在上一期AI文献推荐中,我们为您推荐了强化学习的热点论文,包括基于模型的强化学习、强化学习在量子通信与机器人的应用等方面的文献。
本期我们为您选取了4篇文献,介绍人工智能与边缘计算的最新动态,包括基于RRAM的CMOS集成非易失性存内计算(nvCIM)在AI边缘设备中的应用,无线移动边缘计算网络中基于深度强化学习的在线计算卸载(DROO),移动边缘计算中基于强化学习的延迟感知微服务协调算法,基于边缘计算的按需加速深度神经网络推理框架等文献,推送给相关领域的科研人员。
文献一 基于RRAM的CMOS集成非易失性存内计算在AI边缘设备中的应用
A CMOS-integrated compute-in-memory macro based on resistive random-access memory for AI edge devices
Xue, Cheng-Xin, etc.
NATURE ELECTRONICS, 2021, 4(1): 81-90
Commercial complementary metal-oxide-semiconductor and resistive random-access memory technologies can be used to create multibit compute-in-memory circuits capable of fast and energy-efficient inference for use in small artificial intelligence edge devices.
The development of small, energy-efficient artificial intelligence edge devices is limited in conventional computing architectures by the need to transfer data between the processor and memory. Non-volatile compute-in-memory (nvCIM) architectures have the potential to overcome such issues, but the development of high-bit-precision configurations required for dot-product operations remains challenging. In particular, input-output parallelism and cell-area limitations, as well as signal margin degradation, computing latency in multibit analogue readout operations and manufacturing challenges, still need to be addressed. Here we report a 2 Mb nvCIM macro (which combines memory cells and related peripheral circuitry) that is based on single-level cell resistive random-access memory devices and is fabricated in a 22 nm complementary metal-oxide-semiconductor foundry process. Compared with previous nvCIM schemes, our macro can perform multibit dot-product operations with increased input-output parallelism, reduced cell-array area, improved accuracy, and reduced computing latency and energy consumption. The macro can, in particular, achieve latencies between 9.2 and 18.3 ns, and energy efficiencies between 146.21 and 36.61 tera-operations per second per watt, for binary and multibit input-weight-output configurations, respectively.
阅读原文 https://www.nature.com/articles/s41928-020-00505-5

The proposed nvCIM structure
文献二 无线移动边缘计算网络中基于深度强化学习的在线计算卸载
Deep Reinforcement Learning for Online Computation Offloading in Wireless Powered Mobile-Edge Computing Networks
Huang, Liang, etc.
IEEE TRANSACTIONS ON MOBILE COMPUTING, 2020, 19(11): 2581-2593
Wireless powered mobile-edge computing (MEC) has recently emerged as a promising paradigm to enhance the data processing capability of low-power networks, such as wireless sensor networks and internet of things (IoT). In this paper, we consider a wireless powered MEC network that adopts a binary offloading policy, so that each computation task of wireless devices (WDs) is either executed locally or fully offloaded to an MEC server. Our goal is to acquire an online algorithm that optimally adapts task offloading decisions and wireless resource allocations to the time-varying wireless channel conditions. This requires quickly solving hard combinatorial optimization problems within the channel coherence time, which is hardly achievable with conventional numerical optimization methods. To tackle this problem, we propose a Deep Reinforcement learning-based Online Offloading (DROO) framework that implements a deep neural network as a scalable solution that learns the binary offloading decisions from the experience. It eliminates the need of solving combinatorial optimization problems, and thus greatly reduces the computational complexity especially in large-size networks. To further reduce the complexity, we propose an adaptive procedure that automatically adjusts the parameters of the DROO algorithm on the fly. Numerical results show that the proposed algorithm can achieve near-optimal performance while significantly decreasing the computation time by more than an order of magnitude compared with existing optimization methods. For example, the CPU execution latency of DROO is less than 0.1 second in a 30-user network, making real-time and optimal offloading truly viable even in a fast fading environment.
阅读原文 https://ieeexplore.ieee.org/document/8771176
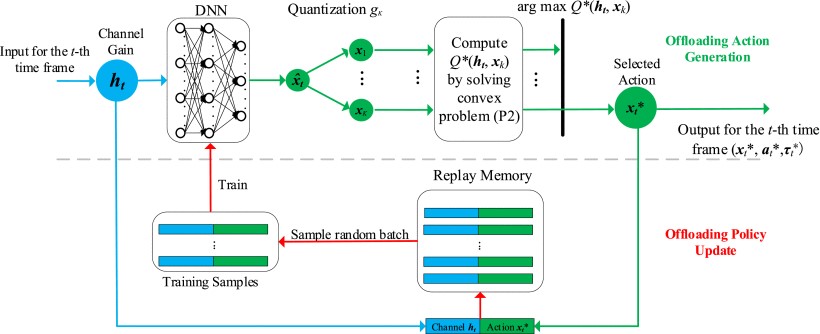 .
.The schematics of the proposed DROO algorithm
文献三 移动边缘计算中基于强化学习的延迟感知微服务协调算法
Delay-Aware Microservice Coordination in Mobile Edge Computing: A Reinforcement Learning Approach
Wang, Shangguang, etc.
IEEE TRANSACTIONS ON MOBILE COMPUTING, 2021, 20(3): 939-951
As an emerging service architecture, microservice enables decomposition of a monolithic web service into a set of independent lightweight services which can be executed independently. With mobile edge computing, microservices can be further deployed in edge clouds dynamically, launched quickly, and migrated across edge clouds easily, providing better services for users in proximity. However, the user mobility can result in frequent switch of nearby edge clouds, which increases the service delay when users move away from their serving edge clouds. To address this issue, this article investigates microservice coordination among edge clouds to enable seamless and real-time responses to service requests from mobile users. The objective of this work is to devise the optimal microservice coordination scheme which can reduce the overall service delay with low costs. To this end, we first propose a dynamic programming-based offline microservice coordination algorithm, that can achieve the globally optimal performance. However, the offline algorithm heavily relies on the availability of the prior information such as computation request arrivals, time-varying channel conditions and edge cloud's computation capabilities required, which is hard to be obtained. Therefore, we reformulate the microservice coordination problem using Markov decision process framework and then propose a reinforcement learning-based online microservice coordination algorithm to learn the optimal strategy. Theoretical analysis proves that the offline algorithm can find the optimal solution while the online algorithm can achieve near-optimal performance. Furthermore, based on two real-world datasets, i.e., the Telecom's base station dataset and Taxi Track dataset from Shanghai, experiments are conducted. The experimental results demonstrate that the proposed online algorithm outperforms existing algorithms in terms of service delay and migration costs, and the achieved performance is close to the optimal performance obtained by the offline algorithm.
阅读原文 https://ieeexplore.ieee.org/document/8924682
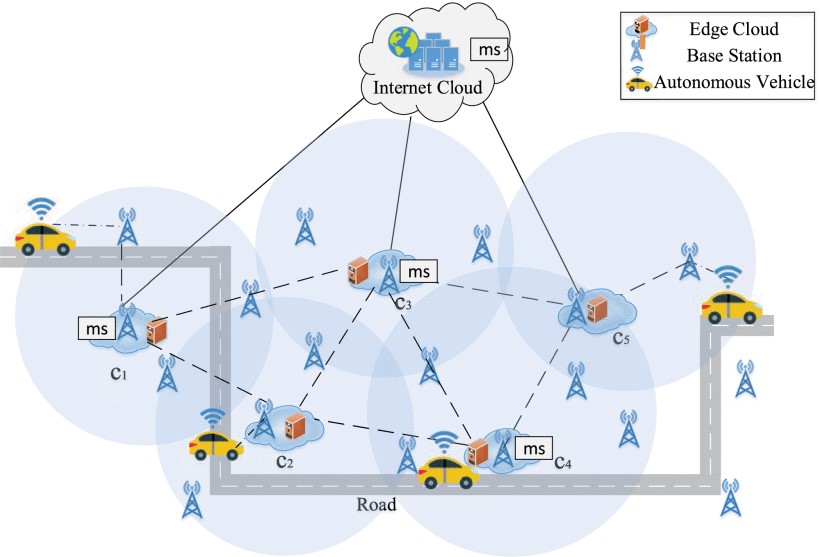
Illustration of microservice coordination in mobile edge computing
文献四 基于边缘计算的按需加速深度神经网络推理框架
Edge AI: On-Demand Accelerating Deep Neural Network Inference via Edge Computing
Li, En, etc.
IEEE TRANSACTIONS ON WIRELESS COMMUNICATIONS, 2020, 19(1): 447-457
As a key technology of enabling Artificial Intelligence (AI) applications in 5G era, Deep Neural Networks (DNNs) have quickly attracted widespread attention. However, it is challenging to run computation-intensive DNN-based tasks on mobile devices due to the limited computation resources. What's worse, traditional cloud-assisted DNN inference is heavily hindered by the significant wide-area network latency, leading to poor real-time performance as well as low quality of user experience. To address these challenges, in this paper, we propose Edgent, a framework that leverages edge computing for DNN collaborative inference through device-edge synergy. Edgent exploits two design knobs: (1) DNN partitioning that adaptively partitions computation between device and edge for purpose of coordinating the powerful cloud resource and the proximal edge resource for real-time DNN inference; (2) DNN right-sizing that further reduces computing latency via early exiting inference at an appropriate intermediate DNN layer. In addition, considering the potential network fluctuation in real-world deployment, Edgent is properly design to specialize for both static and dynamic network environment. Specifically, in a static environment where the bandwidth changes slowly, Edgent derives the best configurations with the assist of regression-based prediction models, while in a dynamic environment where the bandwidth varies dramatically, Edgent generates the best execution plan through the online change point detection algorithm that maps the current bandwidth state to the optimal configuration. We implement Edgent prototype based on the Raspberry Pi and the desktop PC and the extensive experimental evaluations demonstrate Edgent's effectiveness in enabling on-demand low-latency edge intelligence.
阅读原文 https://ieeexplore.ieee.org/document/8876870
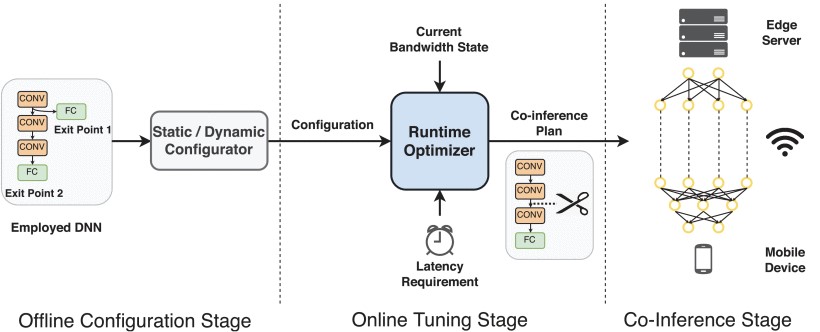
Edgent framework overview
往期精彩推荐
前沿论文带您解读5G应用领域 ——图书馆前沿文献专题推荐服务(2)
热点论文解读AI应用领域 ——图书馆前沿文献专题推荐服务(3)
热点论文带您探究5G和未来通信——图书馆前沿文献专题推荐服务 (4)
前沿文献带您解读自然语言处理技术 ——图书馆前沿文献专题推荐服务(5)
热点论文带您探究5G和未来通信材料技术领域 ——图书馆前沿文献专题推荐服务(6)
热点论文解读AI应用领域 ——图书馆前沿文献专题推荐服务(3)
热点论文带您探究5G和未来通信——图书馆前沿文献专题推荐服务 (4)
前沿文献带您解读自然语言处理技术 ——图书馆前沿文献专题推荐服务(5)
热点论文带您探究5G和未来通信材料技术领域 ——图书馆前沿文献专题推荐服务(6)
热点文献带您关注AI情感分类技术 ——图书馆前沿文献专题推荐服务(7)
热点论文带您探究6G的无限可能——图书馆前沿文献专题推荐服务(8)
热点文献带您关注AI文本摘要自动生成 ——图书馆前沿文献专题推荐服务(9)
热点论文:5G/6G引领社会新进步——图书馆前沿文献专题推荐服务(10)
热点文献带您关注AI机器翻译 ——图书馆前沿文献专题推荐服务(11)
热点论文与您探讨5G/6G网络技术新进展——图书馆前沿文献专题推荐服务(12)
热点文献带您关注AI计算机视觉 ——图书馆前沿文献专题推荐服务(13)
热点论文与带您领略5G/6G的硬科技与新思路 ——图书馆前沿文献专题推荐服务(14)
热点文献带您关注AI计算机视觉 ——图书馆前沿文献专题推荐服务(15)
热点论文带您领略5G/6G的最新技术动向 ——图书馆前沿文献专题推荐服务(18)
热点文献带您关注图神经网络——图书馆前沿文献专题推荐服务(19)
热点论文与带您领略5G/6G材料技术的最新发展——图书馆前沿文献专题推荐服务(20)
热点文献带您关注模式识别——图书馆前沿文献专题推荐服务(21)
热点论文与带您领略6G网络技术的最新发展趋势 ——图书馆前沿文献专题推荐服务(22)
热点文献带您关注机器学习与量子物理 ——图书馆前沿文献专题推荐服务(23)
热点论文与带您领略5G/6G通信器件材料的最新进展 ——图书馆前沿文献专题推荐服务(24)
热点文献带您关注AI自动驾驶——图书馆前沿文献专题推荐服务(25)
热点论文与带您领略5G/6G网络安全和技术的最新进展——图书馆前沿文献专题推荐服务(26)
热点文献带您关注AI神经网络与忆阻器——图书馆前沿文献专题推荐服务(27)
热点论文与带您领略5G/6G电子器件和太赫兹方面的最新进展——图书馆前沿文献专题推荐服务(28)
热点文献带您关注AI与机器人——图书馆前沿文献专题推荐服务(29)
热点论文与带您领略5G/6G热点技术的最新进展——图书馆前沿文献专题推荐服务(30)
热点文献带您关注AI与触觉传感技术——图书馆前沿文献专题推荐服务(31)
热点论文与带您领略5G/6G热点技术的最新进展——图书馆前沿文献专题推荐服务(32)
热点文献带您关注AI深度学习与计算机视觉——图书馆前沿文献专题推荐服务(33)
热点论文与带您领略未来通信的热点技术及最新进展——图书馆前沿文献专题推荐服务(34)
热点文献带您关注AI强化学习——图书馆前沿文献专题推荐服务(35)
热点论文与带您领略5G/6G基础研究的最新进展——图书馆前沿文献专题推荐服务(36)